GPM 模型学习
传统多线程实现并发的缺点
线程的上下文切换:
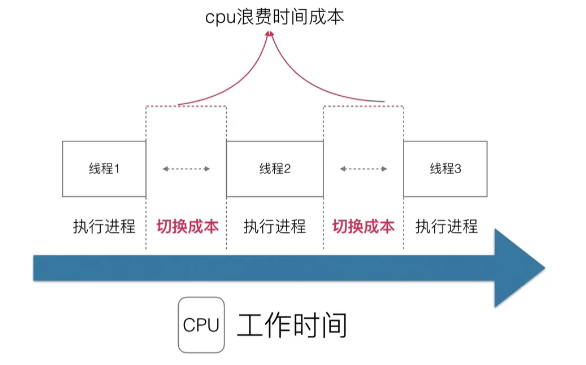
多任务系统往往需要同时执行多道作业。作业数往往大于机器的 CPU 数,然而一颗 CPU 同时只能执行一项任务,为了让用户感觉这些任务正在同时进行,操作系统的设计者巧妙地利用了时间片轮转的方式,CPU 给每个任务都服务一定的时间,然后把当前任务的状态保存下来,在加载下一任务的状态后,继续服务下一任务。任务的状态保存及再加载,这段过程就叫做上下文切换。 时间片轮转的方式使多个任务在同一颗 CPU 上执行变成了可能,但同时也带来了保存现场和加载现场的直接消耗。
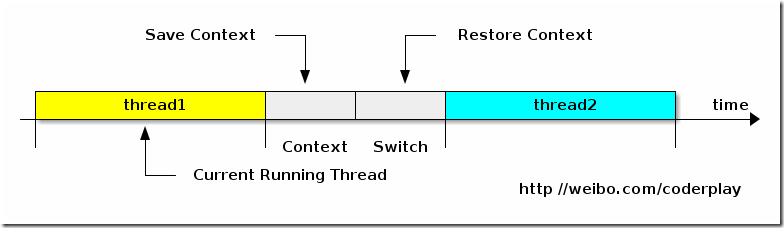
所以进程或线程越多,切换成本就越大,也就越浪费。
而且线程本身占用的内存也是个问题,以 Java 为例,创建一个线程默认需要消耗 1M 的内存,如果每个用户请求都创建一个线程,那么 1024 个用户就是 1G 了,并发量一大就扛不住了(使用池化技术一定程度上解决这个问题,但是 Java 中调用 wait,sleep, lock 操作都会挂起对应的线程,而且线程池本身的管理也造成了心智负担)。
注意:上下文切换带来的消耗,以及线程的利用率是核心问题,至于锁之类的问题,那是线程共享模型的问题,与多线程本身关系不大。
goroutine 基本模型和调度设计
上面上下文切换主要是系统在做,所以协程的思路就是(有栈协程)把线程分成 “用户线程” 和 “内核线程”(真正的线程),用户线程底层绑定内核线程(多对一的关系),用户操作的都是 Go 给用户分配的 “用户线程”,每次上下文切换是操作在堆上模拟的一套栈空间,实际并非系统级的上下文切换。
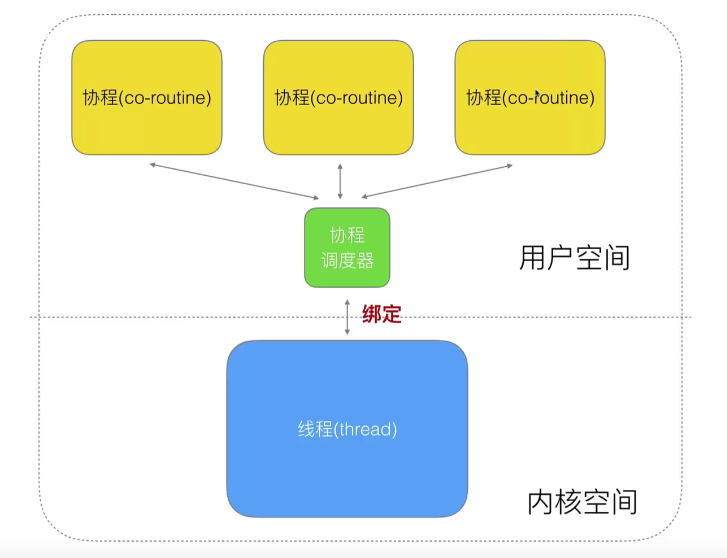
可以理解为 goroutine 是由官方实现的超级 "线程池"。
Go 的线程调度器 GPM
调度算法
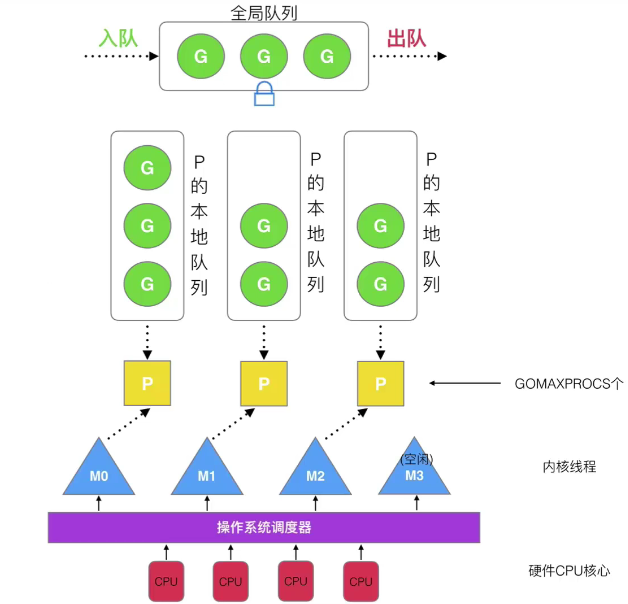
G:表示 Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
P:Processor,表示逻辑处理器, 对 G 来说,P 相当于 CPU 核,G 只有绑定到 P 才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量),P 的数量由用户设置的 GOMAXPROCS 决定,但是不论 GOMAXPROCS 设置为多大,P 的数量最大为 256。可以调用 runtime.NumCPU 函数来查询当前程序可利用的逻辑 CPU 数目。(具体的调节方式参考下面的小节)
M:Machine,OS 线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础,M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
在 GMP 模型中,M 和 P 之间存在着关联和配对的关系,但不是一一对应的。每个 P 可以关联多个 M,但每个 M 只能属于一个 P。P 负责将 Goroutine 分配给可用的 M 进行执行,并负责在 M 阻塞时将其转移到其他可用的 M。这种分配和转移的过程是由 Go 运行时系统自动管理的,开发人员无需显式干预。
调度过程
当一个 G 被创建出来,或者变为可执行状态时,就把他放到 P 的本地可执行队列中,如果满了则放入 Global;
每个 P 维护一个 G 的本地队列;
当一个 G 在 M 里执行结束后,P 会从队列中把该 G 取出;
当 M 执行完了当前 P 的 Local 队列里的所有 G 后,P 也不会就这么在那划水啥都不干,它会先尝试从 Global 队列寻找 G 来执行,如果 Global 队列为空,它会随机挑选另外一个 P,从它的队列里中拿走一半的 G 到自己的队列中执行。
Goroutine 调度策略
队列轮转
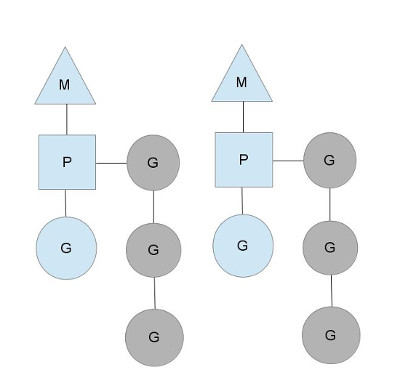
上图中可见每个 P 维护着一个包含 G 的队列,不考虑 G 进入系统调用或 IO 操作的情况下,P 周期性的将 G 调度到 M 中执行,执行一小段时间,将上下文保存下来,然后将 G 放到队列尾部,然后从队列中重新取出一个 G 进行调度。
除了每个 P 维护的 G 队列以外,还有一个全局的队列,每个 P 会周期性的查看全局队列中是否有 G 待运行并将期调度到 M 中执行,全局队列中 G 的来源,主要有从系统调用中恢复的 G。之所以 P 会周期性的查看全局队列,也是为了防止全局队列中的 G 被饿死。
系统调用(或 IO 操作)
上面说到 P 的个数默认等于 CPU 核数,每个 M 必须持有一个 P 才可以执行 G,一般情况下 M 的个数会略大于 P 的个数,这多出来的 M 将会在 G 产生系统调用时发挥作用。类似线程池,Go 也提供一个 M 的池子,需要时从池子中获取,用完放回池子,不够用时就再创建一个。
当 M 运行的某个 G 产生系统调用时,如下图所示:
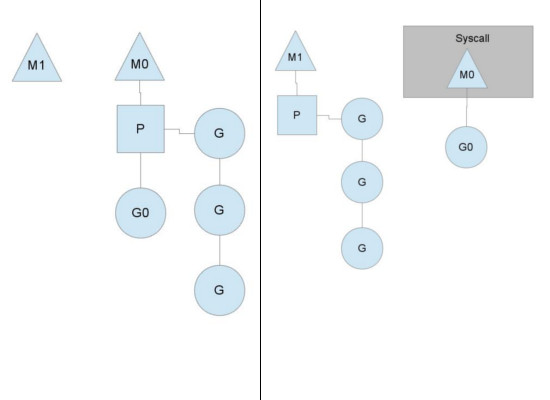
如图所示,当 G0 即将进入系统调用(或者IO 操作)时,M0 将释放 P,进而某个空闲的 M1 获取 P,继续执行 P 队列中剩下的 G。而 M0 由于陷入系统调用(IO 操作)而进被阻塞,M1 接替 M0 的工作,只要 P 不空闲,就可以保证充分利用 CPU。
M1 的来源有可能是 M 的缓存池,也可能是新建的。当 G0 系统调用结束后,跟据 M0 是否能获取到 P,将会将 G0 做不同的处理:
- 如果有空闲的 P,则获取一个 P,继续执行 G0。
- 如果没有空闲的 P,则将 G0 放入全局队列,等待被其他的 P 调度。然后 M0 将进入缓存池睡眠。
工作量窃取
多个 P 中维护的 G 队列有可能是不均衡的,比如下图:
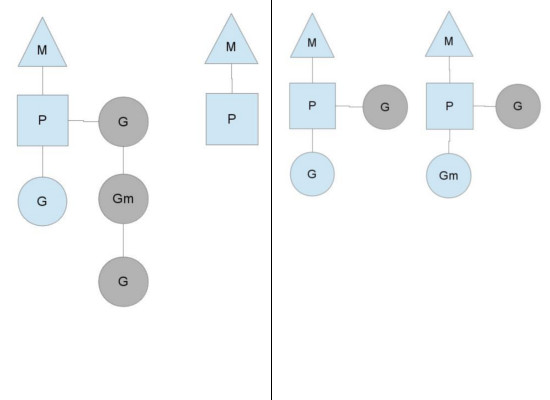
竖线左侧中右边的 P 已经将 G 全部执行完,然后去查询全局队列,全局队列中也没有 G,而另一个 M 中除了正在运行的 G 外,队列中还有 3 个 G 待运行。此时,空闲的 P 会将其他 P 中的 G 偷取一部分过来,一般每次偷取一半。偷取完如右图所示。
GOMAXPROCS 应该怎么样设置?
GOMAXPROCS 是 Go 语言中用于设置并发执行的最大 CPU 核心数的环境变量。它决定了在一个 Go 程序中同时运行的 Goroutine 的数量。合理地设置 GOMAXPROCS 可以充分利用多核 CPU 的性能,并提高程序的并发执行效率。
以下是一些建议,以设置合理的 GOMAXPROCS 值:
默认值:Go 语言的运行时默认将 GOMAXPROCS 设置为可用的 CPU 核心数。在大多数情况下,默认值已经是一个合理的选择,可以让运行时自动根据系统的配置来进行设置。
多核 CPU:如果系统有多个 CPU 核心,并且应用程序是 CPU 密集型的,可以考虑将 GOMAXPROCS 设置为大于默认值的数字,以充分利用所有可用的核心。可以尝试将 GOMAXPROCS 设置为 CPU 核心的数量或略大于它。例如,如果有一个拥有 4 个物理核心和超线程技术(Hyper-Threading)的 CPU,那么可以将 GOMAXPROCS 设置为 8。
IO 密集型任务:对于主要是进行 IO 操作的应用程序,例如网络请求或文件读写等,较小的 GOMAXPROCS 值可能更合适,因为在这种情况下,大量的 Goroutine 可能会导致过多的上下文切换,反而影响性能。通常情况下,将 GOMAXPROCS 设置为 CPU 核心的数量或稍小于它即可。
性能测试与调优:在实际部署应用程序之前,可以进行性能测试和调优,尝试不同的 GOMAXPROCS 值,并测量应用程序的性能指标(例如响应时间、吞吐量等)。通过实验找到最佳的 GOMAXPROCS 设置,以获得最佳的性能表现。
需要注意的是,GOMAXPROCS 的设置是针对每个运行的程序而言的,而不是全局设置。可以在代码中使用 runtime.GOMAXPROCS() 函数来动态设置 GOMAXPROCS 值,或者使用命令行参数 -p 来设置。
使用 GOMAXPROCS 参数来确定需要使用多少个 OS 线程来同时执行 Go 代码(默认值是机器上的 CPU 核心数)
func a() {
for i := 1; i < 10; i++ {
fmt.Println("A:", i)
}
}
func b() {
for i := 1; i < 10; i++ {
fmt.Println("B:", i)
}
}
func main() {
runtime.GOMAXPROCS(1)
go a()
go b()
time.Sleep(time.Second)
}
如上指定了只使用一个线程,此时是做完一个任务再做另一个任务。